Water & Carbon Skills (AQA A Level Geography): Revision Note
Exam code: 7037

Water & Carbon Skills
Geographical skills are working skills essential to developing a synoptic approach to answering questions but also observing the 'bigger picture' in geography
Key terms
Quantitative data is measurable and can be expressed by numbers or placed into specific categories
Often used to test and prove previously specified concepts or hypotheses
Quantitative data is objective as it provides specific values
E.g. Barton-on-Sea beach in Dorset, UK is a short 1.75km, 20m wide, shingle and rock beach, backed by high, clay cliffs of between 5-10m
Qualitative data is descriptive information, usually written and presents features (quality) in an intuitive way
Often used to formulate theories and hypotheses
Qualitative data is subjective because it 'describes' from the angle of the viewer
E.g. The river is fast and dangerous or the wood is dark and feels dangerous
Primary data is data collected first-hand usually during fieldwork
It is real-time data specific to the investigation
E.g. Photograph taken of flood defences or species count using a quadrat
Secondary data is data collected by others and is used in support of primary data
It allows for studies of changes over time - census data collected by the government and compared
E.g. Maps, textbooks, websites, journals etc.
Big data are large datasets that need computational manipulation
Used to show trends, patterns and subsequent links
E.g. Geolocation, geospatial data, GIS (geographic information systems), Google Earth, satellite navigation etc.
Continuous data
Numerical data that can take any value within a given range
E.g. heights and weights
Discrete data
Numerical data that can only take certain values
E.g. shoe size
Line graph
One of the simplest ways to display continuous data
Both axes are numerical and continuous
Used to show changes over time and space
Table Showing Relative Strengths and Limitations of Line Graphs
Strengths | Limitations |
|---|---|
Shows trends and patterns clearly | Does not show causes or effects |
Quicker and easier to construct than a bar graph | Can be misleading if the scales on the axis are altered |
Easy to interpret | If there are multiple lines on a graph it can be confusing |
Anomalies are easy to identify | Often requires additional information to be useful |
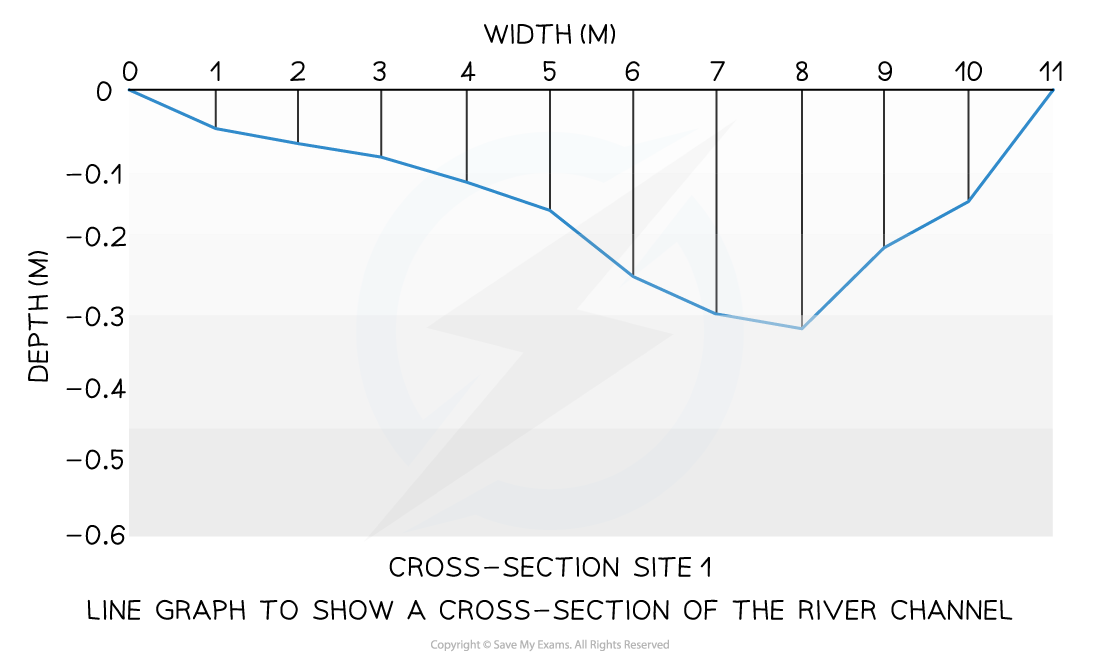
A river cross-section is a particular form of line graph because it is not continuous data, but the plots can be joined to show the shape of the river channel
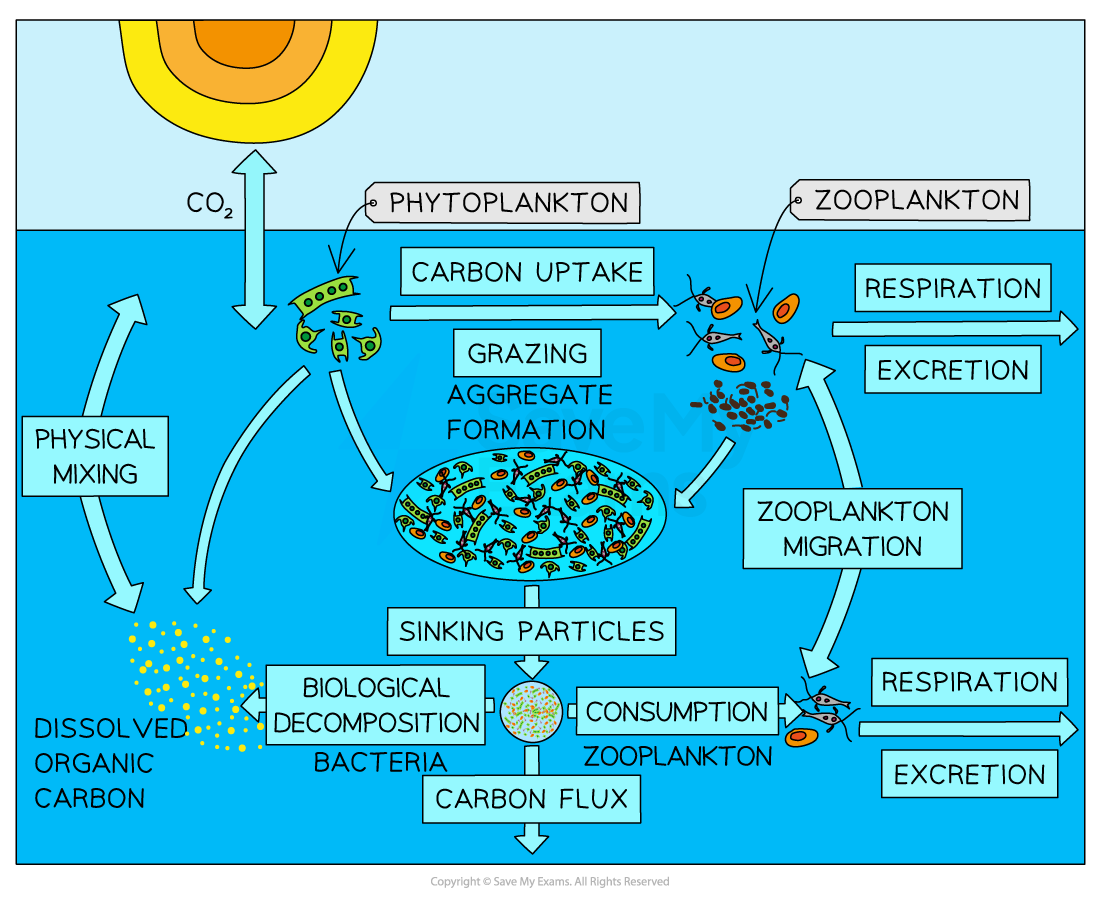
Flow lines
Useful for showing the strength of interaction between variables
Shows direction and volume along a specific path
E.g. the water and carbon cycle use flow lines
The lines can also be displayed to show proportion or importance using size or colour to highlight differences
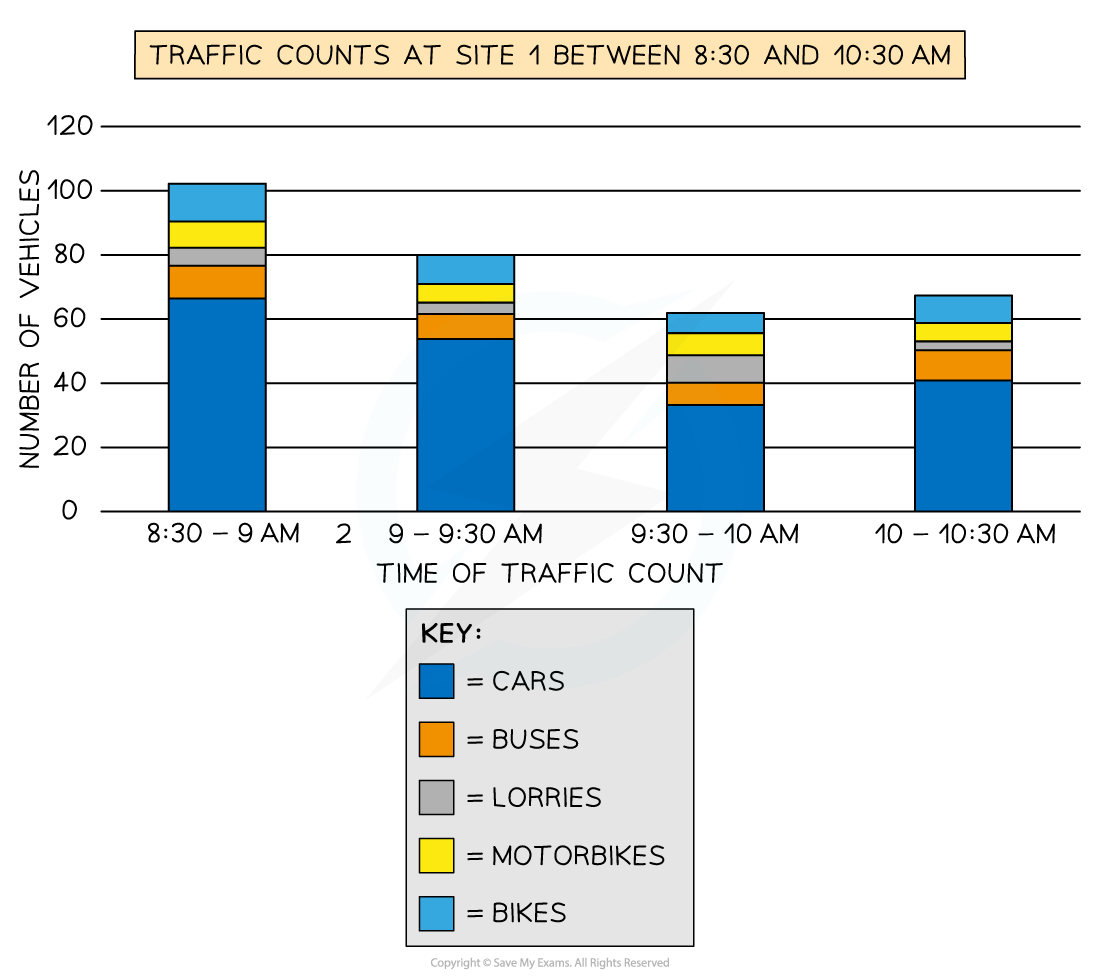
Compound or divided bar chart
The bars are subdivided to show the information with all bars totalling 100%
Divided bar charts show a variety of categories
They can show percentages and frequencies
Table Showing Relative Strengths and Limitations of Compound Graphs
Strengths | Limitations |
|---|---|
A large amount of data can be shown on one graph | A divided bar chart can be difficult to read if there are multiple segments |
Percentages and frequencies can be displayed on divided bar char | Can be difficult to compare sometimes |
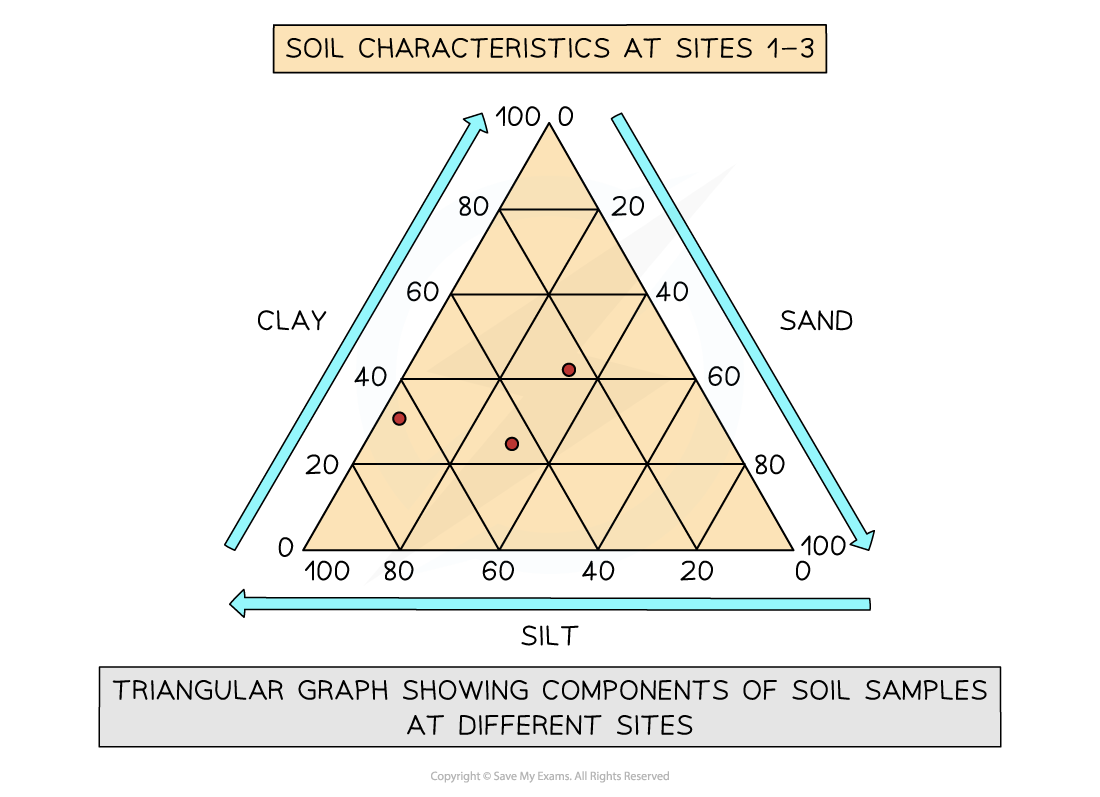
Triangular graph
Have axes on three sides all of which go from 0-100
Used to display data which can be divided into three
The data must be in percentages
Can be used to plot data such as soil content, employment in economic activities
Read each side carefully so you are aware of which direction the data should go in
Examiner Tips and Tricks
In the exam, you will not be asked to draw an entire graph. However, it is common to be asked to complete an unfinished graph using the data provided. You may also be asked to identify anomalous results or to draw the best fit line on a scatter graph.
Take your time to ensure that you have marked the data on the graph accurately
Use the same style as the data which has already been put on the graph
Bars on a bar graph should be the same width
If the dots on a graph are connected by a line you should do the same
Mass balance
Mass balance is the input, output, and distribution of the water or carbon cycle between its flows/transfers within each stage of the system
It accounts for all the material in a process and can be measured locally (a single system) or globally
E.g. a student conducted a mass balance on a drainage basin and they concluded that approximately 84% of the water was directly recycled back to the river while 15% was indirectly returned via plant and sub-surface flows, with the final 1% being removed from the water cycle by deep aquifers
A balanced carbon cycle is the outcome of different components working in dynamic equilibrium with each other
The atmosphere's carbon composition is partly regulated by ocean and terrestrial photosynthesis
Soil health is maintained through decomposition, combustion and carbon storage which is important for ecosystem productivity etc.
Scatter graph
Points should not be connected
The best-fit line can be added to show the relations
Used to show the relationship between two variables
In a river study, they are used to show the relationship between different river characteristics such as the relationship between the width and depth of the river channel
Table Showing Relative Strengths and Limitations of Scatter Graphs
Strengths | Limitations |
|---|---|
Clearly shows data correlation | Data points cannot be labelled |
Shows the spread of data | Too many data points can make it difficult to read |
Makes it easy to identify anomalies and outliers | Can only show the relationship between two sets of data |
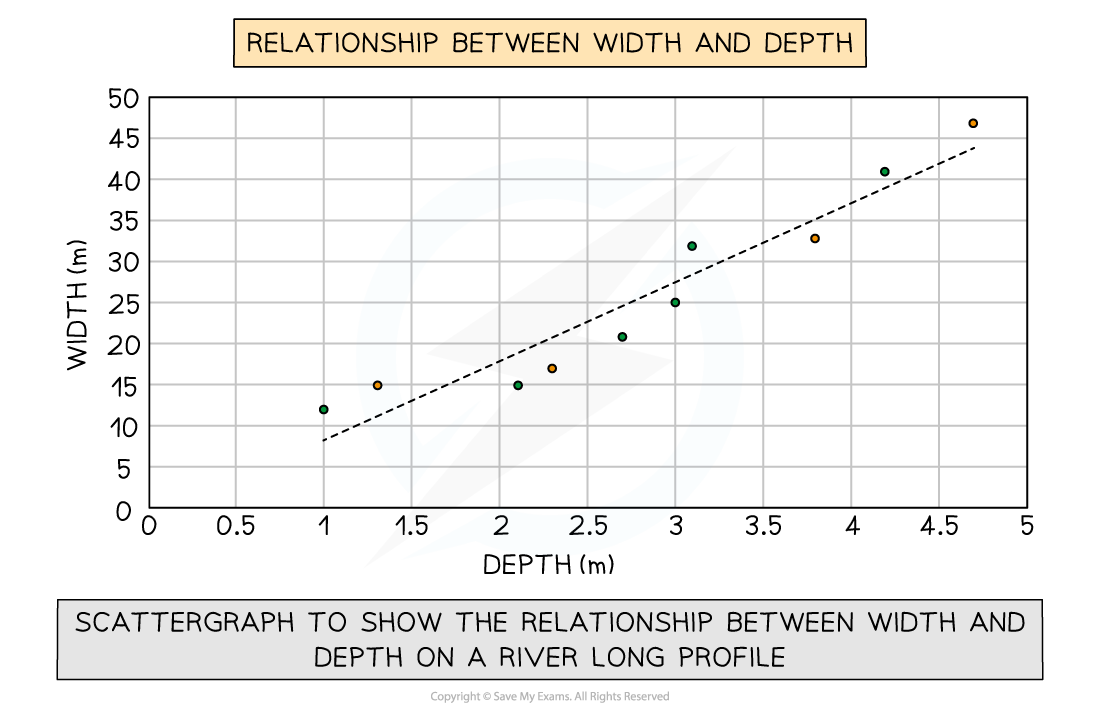
Types of correlation
Positive correlation
As one variable increases, so too does the other
The line of best fit goes from the bottom left to the top right of the graph
Negative correlation
As one variable increases the other decreases
The line of best fit goes from the top left to the bottom right of the graph
No correlation
Data points will have a scattered distribution
There is no relationship between the variables
Examiner Tips and Tricks
Always check when making calculations what the question has asked you to do. Is it asking for units to be stated or calculate to the nearest whole number or quote to 2 decimal places.
Worked Example
Making predictions from a set of data
Study Figure 1 below, which shows the cost against distance travelled
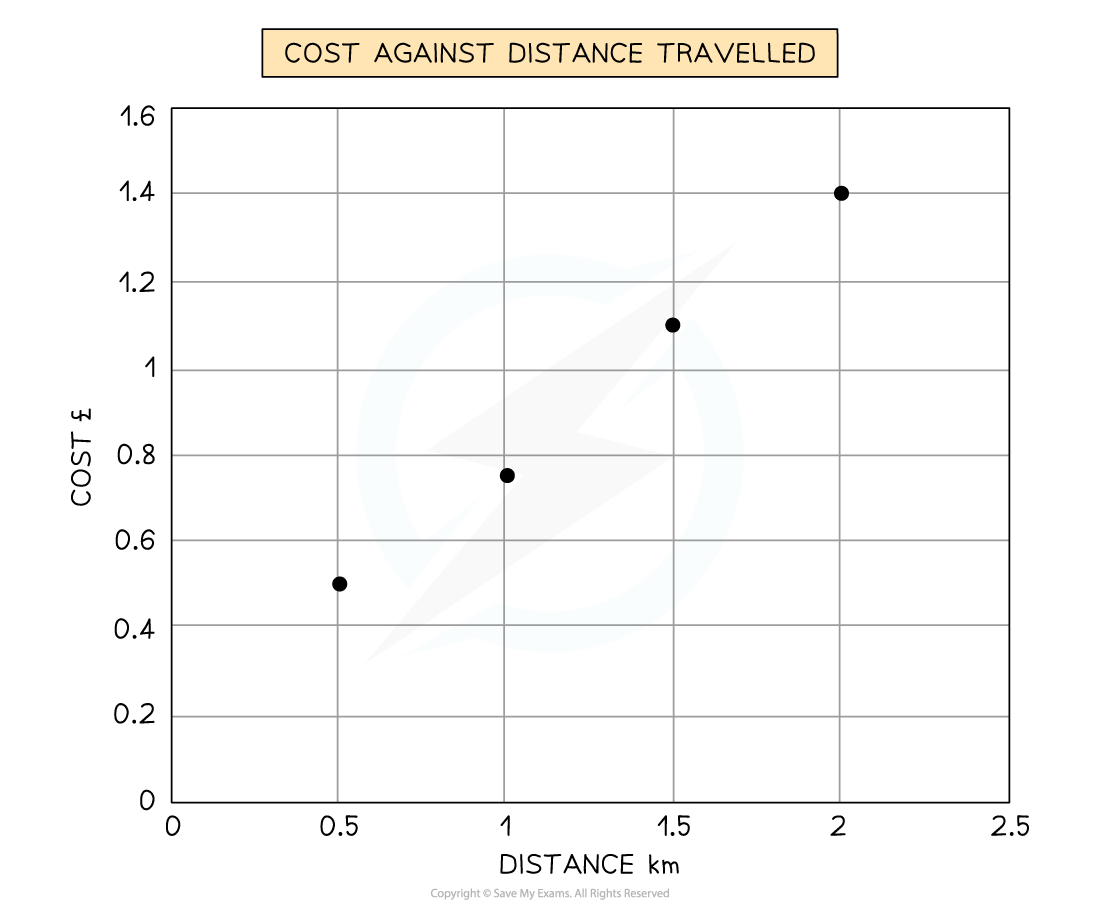
Figure 1
Predict what the cost at would be at 1.75km
[1 mark]
You may be asked to make a prediction for the next step in given data (either table or graph form) in your exam
Study the data carefully
Look at the direction in which the data is going
Are the numbers increasing or decreasing?
Is there a clear pattern forming?
E.g. does the data point value change by 3, 4, 6 etc. each time
Answer:
To predict the cost at 1.75 km, find the cost at 1.5 km and 2.0 km
Produce a line of best fit to predict the value at 1.75 km
Cost would be £1.3 [1]
Percentage and percentage change
To give the amount A as a percentage of sample B, divide A by B and multiply by 100
In 2020, 25 out of 360 homes in Catland were burgled
What is the percentage (to the nearest whole number) of homes burgled?
A percentage change shows by how much something has either increased or decreased
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2232%22%3EP%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%2232%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2223.5%22%20y%3D%2232%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2231.5%22%20y%3D%2232%22%3Ec%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2240.5%22%20y%3D%2232%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2250.5%22%20y%3D%2232%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2258.5%22%20y%3D%2232%22%3Et%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2265.5%22%20y%3D%2232%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2275.5%22%20y%3D%2232%22%3Eg%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2284.5%22%20y%3D%2232%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%2299.5%22%20y%3D%2232%22%3Ec%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22109.5%22%20y%3D%2232%22%3Eh%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22118.5%22%20y%3D%2232%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22128.5%22%20y%3D%2232%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22138.5%22%20y%3D%2232%22%3Eg%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22147.5%22%20y%3D%2232%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1c1c4b4ae53f75347cab9713082%22%20font-size%3D%2217%22%20text-anchor%3D%22middle%22%20x%3D%22167.5%22%20y%3D%2232%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22178.5%22%20x2%3D%22412.5%22%20y1%3D%2225.5%22%20y2%3D%2225.5%22%2F%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22184.5%22%20y%3D%2218%22%3Ef%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22193.5%22%20y%3D%2218%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22201.5%22%20y%3D%2218%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22210.5%22%20y%3D%2218%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22218.5%22%20y%3D%2218%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22232.5%22%20y%3D%2218%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22241.5%22%20y%3D%2218%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22249.5%22%20y%3D%2218%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22257.5%22%20y%3D%2218%22%3Eu%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22266.5%22%20y%3D%2218%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1c1c4b4ae53f75347cab9713082%22%20font-size%3D%2217%22%20text-anchor%3D%22middle%22%20x%3D%22286.5%22%20y%3D%2218%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22300.5%22%20y%3D%2218%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22308.5%22%20y%3D%2218%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22315.5%22%20y%3D%2218%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22323.5%22%20y%3D%2218%22%3Eg%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22331.5%22%20y%3D%2218%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22339.5%22%20y%3D%2218%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22348.5%22%20y%3D%2218%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22356.5%22%20y%3D%2218%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22370.5%22%20y%3D%2218%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22379.5%22%20y%3D%2218%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22387.5%22%20y%3D%2218%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22395.5%22%20y%3D%2218%22%3Eu%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22404.5%22%20y%3D%2218%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22243.5%22%20y%3D%2245%22%3Eo%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22251.5%22%20y%3D%2245%22%3Er%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22258.5%22%20y%3D%2245%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22266.5%22%20y%3D%2245%22%3Eg%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22274.5%22%20y%3D%2245%22%3Ei%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22282.5%22%20y%3D%2245%22%3En%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22291.5%22%20y%3D%2245%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22299.5%22%20y%3D%2245%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22313.5%22%20y%3D%2245%22%3Ev%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22322.5%22%20y%3D%2245%22%3Ea%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22330.5%22%20y%3D%2245%22%3El%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22338.5%22%20y%3D%2245%22%3Eu%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20text-anchor%3D%22middle%22%20x%3D%22347.5%22%20y%3D%2245%22%3Ee%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1c1c4b4ae53f75347cab9713082%22%20font-size%3D%2217%22%20text-anchor%3D%22middle%22%20x%3D%22424.5%22%20y%3D%2232%22%3E%26%23xD7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20text-anchor%3D%22middle%22%20x%3D%22448.5%22%20y%3D%2232%22%3E100%3C%2Ftext%3E%3C%2Fsvg%3E)
In 2021 only 21 houses were burgled. What is the percentage change in Catland?
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cline%20stroke%3D%22%23000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%222.5%22%20x2%3D%2265.5%22%20y1%3D%2225.5%22%20y2%3D%2225.5%22%2F%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20text-anchor%3D%22middle%22%20x%3D%2215.5%22%20y%3D%2218%22%3E21%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e005713ad92b2779a51fe4a253%22%20font-size%3D%2217%22%20text-anchor%3D%22middle%22%20x%3D%2234.5%22%20y%3D%2218%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20text-anchor%3D%22middle%22%20x%3D%2253.5%22%20y%3D%2218%22%3E25%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20text-anchor%3D%22middle%22%20x%3D%2234.5%22%20y%3D%2245%22%3E25%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e005713ad92b2779a51fe4a253%22%20font-size%3D%2217%22%20text-anchor%3D%22middle%22%20x%3D%2277.5%22%20y%3D%2232%22%3E%26%23xD7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20text-anchor%3D%22middle%22%20x%3D%22101.5%22%20y%3D%2232%22%3E100%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e005713ad92b2779a51fe4a253%22%20font-size%3D%2217%22%20text-anchor%3D%22middle%22%20x%3D%22125.5%22%20y%3D%2232%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1e005713ad92b2779a51fe4a253%22%20font-size%3D%2217%22%20text-anchor%3D%22middle%22%20x%3D%22143.5%22%20y%3D%2232%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20text-anchor%3D%22middle%22%20x%3D%22162.5%22%20y%3D%2232%22%3E16%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20text-anchor%3D%22middle%22%20x%3D%22181.5%22%20y%3D%2232%22%3E%25%3C%2Ftext%3E%3C%2Fsvg%3E)
There has been a decrease of 16% in the rate of burglaries in the Catland area
Remember that a positive figure shows an increase but a negative is a decrease
Worked Example
Study Figure 1 and analyse the data presented.
[6 marks]
Figure 1: change in greenhouse gas (GHG) emissions, grouped by relative wealth of country, between 1970 and 2010
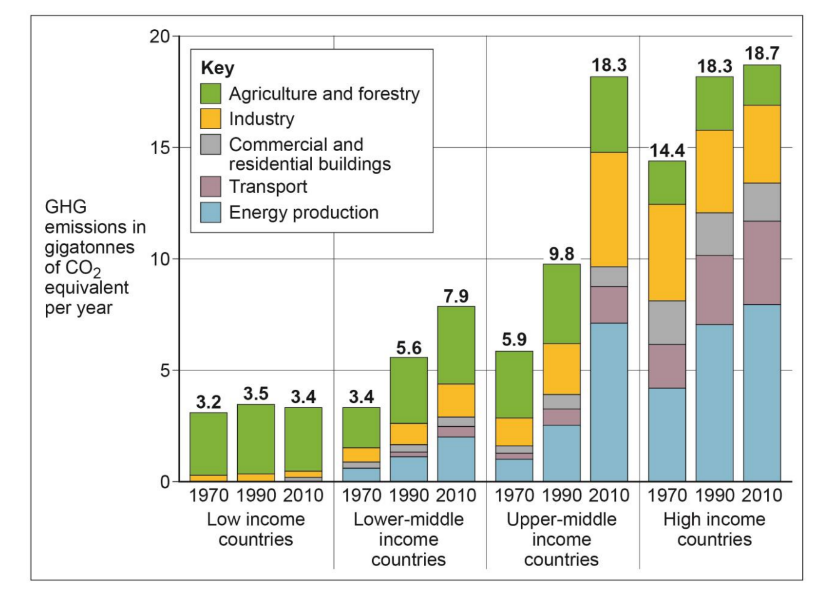
The best answers will use and manipulate the data; spot trends and anomalies, and make clear connections between different aspects of the data and evidence
Answer:
Figure 1 shows that high income countries are still the biggest contributors to GHG production [1] but that there has been little growth between 1990 and 2010 in particular (0.4 Gigatonnes of CO2) [1]. It is upper-middle income countries that have seen the fastest rates of growth of the time periods [1]. For instance, there has been an almost doubling from 9.8 to 18.3 gigatonnes of CO2 produced. Industry appears to have more than doubled in its contribution to GHG in this group of countries (from approximately to 2 to around 5 gigatonnes) [1d].
Low and low-middle income countries contribute relatively little to the overall GHG emissions [1], with LICs emissions appear to be shrinking. For instance, combined in 2010 they produced only 11.3 gigatonnes [1], 7.4 gigatonnes less than high income countries [1]. These countries greatest contribution comes through agriculture (especially for low income countries) with very little through energy use and transport [1].
Statistical Skills
This is the study and handling of data, which includes ways of gathering, reviewing, analysing, and drawing conclusions from data
Mean, median, mode and range
Mean = average value (all the values added and divided by the number of items)
Median = middle value when ordered in size
Mode = most common value
Range = difference between the highest value and lowest value
Sample site | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
Number of pebbles | 184 | 90 | 159 | 142 | 64 | 64 | 95 |
Taking the example above to calculate:
Mean -
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cline%20stroke%3D%22%23000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%222.5%22%20x2%3D%22308.5%22%20y1%3D%2249.5%22%20y2%3D%2249.5%22%2F%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2221.5%22%20y%3D%2242%22%3E184%3C%2Ftext%3E%3Ctext%20font-family%3D%22math12ed72e0d2d50af08c235c494fe%22%20font-size%3D%2217%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2247.5%22%20y%3D%2242%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2268.5%22%20y%3D%2242%22%3E90%3C%2Ftext%3E%3Ctext%20font-family%3D%22math12ed72e0d2d50af08c235c494fe%22%20font-size%3D%2217%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2288.5%22%20y%3D%2242%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22114.5%22%20y%3D%2242%22%3E159%3C%2Ftext%3E%3Ctext%20font-family%3D%22math12ed72e0d2d50af08c235c494fe%22%20font-size%3D%2217%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22140.5%22%20y%3D%2242%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22166.5%22%20y%3D%2242%22%3E142%3C%2Ftext%3E%3Ctext%20font-family%3D%22math12ed72e0d2d50af08c235c494fe%22%20font-size%3D%2217%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22192.5%22%20y%3D%2242%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22213.5%22%20y%3D%2242%22%3E64%3C%2Ftext%3E%3Ctext%20font-family%3D%22math12ed72e0d2d50af08c235c494fe%22%20font-size%3D%2217%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22233.5%22%20y%3D%2242%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22254.5%22%20y%3D%2242%22%3E64%3C%2Ftext%3E%3Ctext%20font-family%3D%22math12ed72e0d2d50af08c235c494fe%22%20font-size%3D%2217%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22274.5%22%20y%3D%2242%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22295.5%22%20y%3D%2242%22%3E95%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22155.5%22%20y%3D%2269%22%3E7%3C%2Ftext%3E%3Ctext%20font-family%3D%22math12ed72e0d2d50af08c235c494fe%22%20font-size%3D%2217%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22320.5%22%20y%3D%2256%22%3E%3D%3C%2Ftext%3E%3Cline%20stroke%3D%22%23000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%22332.5%22%20x2%3D%22370.5%22%20y1%3D%2249.5%22%20y2%3D%2249.5%22%2F%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22351.5%22%20y%3D%2242%22%3E798%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22351.5%22%20y%3D%2269%22%3E7%3C%2Ftext%3E%3Ctext%20font-family%3D%22math12ed72e0d2d50af08c235c494fe%22%20font-size%3D%2217%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22382.5%22%20y%3D%2256%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22408.5%22%20y%3D%2256%22%3E114%3C%2Ftext%3E%3C%2Fsvg%3E)
Median - reordering by size =
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2222%22%20text-anchor%3D%22middle%22%20x%3D%2211.5%22%20y%3D%2220%22%3E64%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2222%22%20text-anchor%3D%22middle%22%20x%3D%2238.5%22%20y%3D%2220%22%3E64%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2222%22%20text-anchor%3D%22middle%22%20x%3D%2265.5%22%20y%3D%2220%22%3E90%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000%22%20font-family%3D%22brack_sm4e06b854ad106cdec1d8cc9%22%20font-size%3D%2222%22%20text-anchor%3D%22start%22%20x%3D%2282.5%22%20y%3D%229%22%3E%26%23x23A1%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000%22%20font-family%3D%22brack_sm4e06b854ad106cdec1d8cc9%22%20font-size%3D%2222%22%20text-anchor%3D%22start%22%20x%3D%2282.5%22%20y%3D%2216%22%3E%26%23x23A2%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000%22%20font-family%3D%22brack_sm4e06b854ad106cdec1d8cc9%22%20font-size%3D%2222%22%20text-anchor%3D%22start%22%20x%3D%2282.5%22%20y%3D%2223%22%3E%26%23x23A3%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000%22%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2222%22%20text-anchor%3D%22middle%22%20x%3D%22100.5%22%20y%3D%2220%22%3E95%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000%22%20font-family%3D%22brack_sm4e06b854ad106cdec1d8cc9%22%20font-size%3D%2222%22%20text-anchor%3D%22start%22%20x%3D%22112.5%22%20y%3D%229%22%3E%26%23x23A4%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000%22%20font-family%3D%22brack_sm4e06b854ad106cdec1d8cc9%22%20font-size%3D%2222%22%20text-anchor%3D%22start%22%20x%3D%22112.5%22%20y%3D%2216%22%3E%26%23x23A5%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000%22%20font-family%3D%22brack_sm4e06b854ad106cdec1d8cc9%22%20font-size%3D%2222%22%20text-anchor%3D%22start%22%20x%3D%22112.5%22%20y%3D%2223%22%3E%26%23x23A6%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2222%22%20text-anchor%3D%22middle%22%20x%3D%22140.5%22%20y%3D%2220%22%3E142%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2222%22%20text-anchor%3D%22middle%22%20x%3D%22178.5%22%20y%3D%2220%22%3E159%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2222%22%20text-anchor%3D%22middle%22%20x%3D%22216.5%22%20y%3D%2220%22%3E184%3C%2Ftext%3E%3C%2Fsvg%3E) = 95 is the middle value
= 95 is the middle valueMode - only 64 appears more than once
Range -
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%2213.5%22%20y%3D%2216%22%3E184%3C%2Ftext%3E%3Ctext%20font-family%3D%22math135b31cfba37a56451b4768509d%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2239.5%22%20y%3D%2216%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%2261.5%22%20y%3D%2216%22%3E64%3C%2Ftext%3E%3Ctext%20font-family%3D%22math135b31cfba37a56451b4768509d%22%20font-size%3D%2216%22%20text-anchor%3D%22middle%22%20x%3D%2282.5%22%20y%3D%2216%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2218%22%20text-anchor%3D%22middle%22%20x%3D%22108.5%22%20y%3D%2216%22%3E120%3C%2Ftext%3E%3C%2Fsvg%3E)
Upper, lower and inter quartile range
These are the values of a quarter (25%) [lower quartile (LQ)] and three-quarters (75%) [upper (UQ)] of the ordered data
No. of shoppers | 2 | 3 | 6 | 6 | 7 | 9 | 13 | 14 | 17 | 22 | 22 |
|
|
| Lower quartile |
|
| Median |
|
| Upper quartile |
|
|
The interquartile range (IQR) is the difference between the upper (UQ) and lower quartile (LQ)
It measures the spread (dispersion) of data around the median
A large number shows the numbers are fairly spread, whereas, a small number shows the data is close to the median
UQ - LQ = IQ [
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2211.5%22%20y%3D%2218%22%3E17%3C%2Ftext%3E%3Ctext%20font-family%3D%22math135b31cfba37a56451b4768509d%22%20font-size%3D%2217%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2237.5%22%20y%3D%2218%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2258.5%22%20y%3D%2218%22%3E6%3C%2Ftext%3E%3Ctext%20font-family%3D%22math135b31cfba37a56451b4768509d%22%20font-size%3D%2217%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2279.5%22%20y%3D%2218%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22106.5%22%20y%3D%2218%22%3E11%3C%2Ftext%3E%3C%2Fsvg%3E) ]
]
Standard deviation
This measures dispersion more reliably than IQR and the symbol for it is 'σ' (sigma)
The formula is
%3C%2Fmo%3E%3C%2Fmrow%3E%3Cmn%20mathvariant%3D%22bold%22%3E2%3C%2Fmn%3E%3C%2Fmsup%3E%3C%2Fmrow%3E%3Cmi%20mathvariant%3D%22bold%22%3En%3C%2Fmi%3E%3C%2Fmfrac%3E%3C%2Fmsqrt%3E%3C%2Fmstyle%3E%3C%2Fmath%3E--%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%40font-face%7Bfont-family%3A'horizontalbf65417dcecc7f2b0006e'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMlJxIOAAAADMAAAATmNtYXCwg0j%2FAAABHAAAADRjdnQgAAcAAAAAAVAAAAACZ2x5ZuwE1kUAAAFUAAAAO2hlYWQNciGiAAABkAAAADZoaGVhBusXCAAAAcgAAAAkaG10eGjtB6sAAAHsAAAACGxvY2EAAYSYAAAB9AAAAAxtYXhwBLEEbgAAAgAAAAAgbmFtZReja%2F8AAAIgAAAByXBvc3QB9wD6AAAD7AAAACBwcmVwu5WEAAAABAwAAAAHAAACRwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAACOv8xEDev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACAAAAAEAAQAAQAAI6%2F%2F%2FwAAI6%2F%2F%2F9xSAAEAAAAAAAcAAAABAAABVQGrAasAAwAjGAGwBBCwATywARCwAtSwAhCwBTwAsAQQsAHUsAEQsADUMDERFSE1AasBq1ZWAAABAAAAAQAARVMXc18PPPUAAwQA%2F%2F%2F%2F%2F9Wt7tH%2F%2F%2F%2F%2F1a3u0QAAAAADAAMAAAAACgACAAEAAAAAAAEAAAPo%2F2oAABdwAAD%2F%2FwMAAAEAAAAAAAAAAAAAAAAAAAACAyAAAAGrAAAAAAAAAAAAAAAAADsAAQAAAAIADQACAAAAAAACAIAEAAAAAAAEAABfAAAAAAAAABUBAgAAAAAAAAABAB4AAAAAAAAAAAACAA4AHgAAAAAAAAADADwALAAAAAAAAAAEAB4AaAAAAAAAAAAFABYAhgAAAAAAAAAGAA8AnAAAAAAAAAAIABwAqwABAAAAAAABAB4AAAABAAAAAAACAA4AHgABAAAAAAADADwALAABAAAAAAAEAB4AaAABAAAAAAAFABYAhgABAAAAAAAGAA8AnAABAAAAAAAIABwAqwADAAEECQABAB4AAAADAAEECQACAA4AHgADAAEECQADADwALAADAAEECQAEAB4AaAADAAEECQAFABYAhgADAAEECQAGAA8AnAADAAEECQAIABwAqwBIAG8AcgBpAHoAbwBuAHQAYQBsACAARgBvAG4AdABSAGUAZwB1AGwAYQByAE0AYQB0AGgAcwAgAEYAbwByACAATQBvAHIAZQAgAEgAbwByAGkAegBvAG4AdABhAGwAIABGAG8AbgB0AEgAbwByAGkAegBvAG4AdABhAGwAIABGAG8AbgB0AFYAZQByAHMAaQBvAG4AIAAxAC4AMEhvcml6b250YWxfRm9udABNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAAAAAAwAAAAAAAAH0APoAAAAAAAAAAAAAAAAAAAAAAAAAALkH%2FwACjYUA)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math143f4d31b04031e49f5eb18baba'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAADxjdnQgDVUNBwAAAVgAAAA6Z2x5ZoPi2VsAAAGUAAAA%2FGhlYWQQC2qxAAACkAAAADZoaGVhCGsXSAAAAsgAAAAkaG10eE2rRkcAAALsAAAADGxvY2EAHTwYAAAC%2BAAAABBtYXhwBT0FPgAAAwgAAAAgbmFtZaBxlY4AAAMoAAABn3Bvc3QB9wD6AAAEyAAAACBwcmVwa1uragAABOgAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACAD0iEv%2F%2FAAAAPSIS%2F%2F%2F%2FxN3wAAEAAAAAAAAAAAFUAywAgAEAAFYAKgJYAh4BDgEsAiwAWgGAAoAAoADUAIAAAAAAAAAAKwBVAIAAqwDVAQABKwAHAAAAAgBVAAADAAOrAAMABwAAMxEhESUhESFVAqv9qwIA%2FgADq%2FxVVQMAAAIAgADrAtUCFQADAAcAZRgBsAgQsAbUsAYQsAXUsAgQsAHUsAEQsADUsAYQsAc8sAUQsAQ8sAEQsAI8sAAQsAM8ALAIELAG1LAGELAH1LAHELAB1LABELAC1LAGELAFPLAHELAEPLABELAAPLACELADPDEwEyE1IR0BITWAAlX9qwJVAcBV1VVVAAEAgAFVAtUBqwADADAYAbAEELEAA%2FawAzyxAgf1sAE8sQUD5gCxAAATELEABuWxAAETELABPLEDBfWwAjwTIRUhgAJV%2FasBq1YAAQAAAAEAANV4zkFfDzz1AAMEAP%2F%2F%2F%2F%2FWOhNz%2F%2F%2F%2F%2F9Y6E3MAAP8gBIADqwAAAAoAAgABAAAAAAABAAAD6P9qAAAXcAAA%2F7YEgAABAAAAAAAAAAAAAAAAAAAAAwNSAFUDVgCAA1YAgAAAAAAAAAAoAAAAsgAAAPwAAQAAAAMAXgAFAAAAAAACAIAEAAAAAAAEAADeAAAAAAAAABUBAgAAAAAAAAABABIAAAAAAAAAAAACAA4AEgAAAAAAAAADADAAIAAAAAAAAAAEABIAUAAAAAAAAAAFABYAYgAAAAAAAAAGAAkAeAAAAAAAAAAIABwAgQABAAAAAAABABIAAAABAAAAAAACAA4AEgABAAAAAAADADAAIAABAAAAAAAEABIAUAABAAAAAAAFABYAYgABAAAAAAAGAAkAeAABAAAAAAAIABwAgQADAAEECQABABIAAAADAAEECQACAA4AEgADAAEECQADADAAIAADAAEECQAEABIAUAADAAEECQAFABYAYgADAAEECQAGAAkAeAADAAEECQAIABwAgQBNAGEAdABoACAARgBvAG4AdABSAGUAZwB1AGwAYQByAE0AYQB0AGgAcwAgAEYAbwByACAATQBvAHIAZQAgAE0AYQB0AGgAIABGAG8AbgB0AE0AYQB0AGgAIABGAG8AbgB0AFYAZQByAHMAaQBvAG4AIAAxAC4AME1hdGhfRm9udABNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAAAMAAAAAAAAB9AD6AAAAAAAAAAAAAAAAAAAAAAAAAAC5BxEAAI2FGACyAAAAFRQTsQABPw%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'round_brackets18549f92a457f2409'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMjwHLFQAAADMAAAATmNtYXDf7xCrAAABHAAAADxjdnQgBAkDLgAAAVgAAAASZ2x5ZmAOz2cAAAFsAAABJGhlYWQOKih8AAACkAAAADZoaGVhCvgVwgAAAsgAAAAkaG10eCA6AAIAAALsAAAADGxvY2EAAARLAAAC%2BAAAABBtYXhwBIgEWQAAAwgAAAAgbmFtZXHR30MAAAMoAAACOXBvc3QDogHPAAAFZAAAACBwcmVwupWEAAAABYQAAAAHAAAGcgGQAAUAAAgACAAAAAAACAAIAAAAAAAAAQIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAo8AMGe%2F57AAAHPgGyAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACgAKf%2F%2FAAAAKAAp%2F%2F%2F%2F2f%2FZAAEAAAAAAAAAAAFUAFYBAAAsAKgDgAAyAAcAAAACAAAAKgDVA1UAAwAHAAA1MxEjEyMRM9XVq4CAKgMr%2FQAC1QABAAD%2B0AIgBtAACQBNGAGwChCwA9SwAxCwAtSwChCwBdSwBRCwANSwAxCwBzywAhCwCDwAsAoQsAPUsAMQsAfUsAoQsAXUsAoQsADUsAMQsAI8sAcQsAg8MTAREAEzABEQASMAAZCQ%2FnABkJD%2BcALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAA%2FtACIAbQAAkATRgBsAoQsAPUsAMQsALUsAoQsAXUsAUQsADUsAMQsAc8sAIQsAg8ALAKELAD1LADELAH1LAKELAF1LAKELAA1LADELACPLAHELAIPDEwARABIwAREAEzAAIg%2FnCQAZD%2BcJABkALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAAAAEAAPW2NYFfDzz1AAMIAP%2F%2F%2F%2F%2FVre7u%2F%2F%2F%2F%2F9Wt7u4AAP7QA7cG0AAAAAoAAgABAAAAAAABAAAHPv5OAAAXcAAA%2F%2F4DtwABAAAAAAAAAAAAAAAAAAAAAwDVAAACIAAAAiAAAAAAAAAAAAAkAAAAowAAASQAAQAAAAMACgACAAAAAAACAIAEAAAAAAAEAABNAAAAAAAAABUBAgAAAAAAAAABAD4AAAAAAAAAAAACAA4APgAAAAAAAAADAFwATAAAAAAAAAAEAD4AqAAAAAAAAAAFABYA5gAAAAAAAAAGAB8A%2FAAAAAAAAAAIABwBGwABAAAAAAABAD4AAAABAAAAAAACAA4APgABAAAAAAADAFwATAABAAAAAAAEAD4AqAABAAAAAAAFABYA5gABAAAAAAAGAB8A%2FAABAAAAAAAIABwBGwADAAEECQABAD4AAAADAAEECQACAA4APgADAAEECQADAFwATAADAAEECQAEAD4AqAADAAEECQAFABYA5gADAAEECQAGAB8A%2FAADAAEECQAIABwBGwBSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAAUgBvAHUAbgBkACAAYgByAGEAYwBrAGUAdABzACAAdwBpAHQAaAAgAGEAcwBjAGUAbgB0ACAAMQA4ADUANABSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFYAZQByAHMAaQBvAG4AIAAyAC4AMFJvdW5kX2JyYWNrZXRzX3dpdGhfYXNjZW50XzE4NTQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAADnwHPAAAAAAAAAAAAAAAAAAAAAAAAAAC5B%2F8AAY2FAA%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2222%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%226.5%22%20y%3D%2244%22%3E%26%23x3C3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22math143f4d31b04031e49f5eb18baba%22%20font-size%3D%2219%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2231.5%22%20y%3D%2244%22%3E%3D%3C%2Ftext%3E%3Cpolyline%20fill%3D%22none%22%20points%3D%2216%2C-56%2015%2C-56%207%2C1%202%2C-22%22%20stroke%3D%22%23000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20transform%3D%22translate(43.5%2C61.5)%22%2F%3E%3Cpolyline%20fill%3D%22none%22%20points%3D%227%2C1%202%2C-22%201%2C-19%22%20stroke%3D%22%23000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20transform%3D%22translate(43.5%2C61.5)%22%2F%3E%3Cline%20stroke%3D%22%23000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2259.5%22%20x2%3D%22178.5%22%20y1%3D%225.5%22%20y2%3D%225.5%22%2F%3E%3Cline%20stroke%3D%22%23000%22%20stroke-linecap%3D%22square%22%20stroke-width%3D%221%22%20x1%3D%2265.5%22%20x2%3D%22172.5%22%20y1%3D%2236.5%22%20y2%3D%2236.5%22%2F%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2222%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2274.5%22%20y%3D%2228%22%3E%26%23x3A3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2222%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2292.5%22%20y%3D%2228%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2222%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22102.5%22%20y%3D%2228%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math143f4d31b04031e49f5eb18baba%22%20font-size%3D%2219%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22124.5%22%20y%3D%2228%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22horizontalbf65417dcecc7f2b0006e%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22147.5%22%20y%3D%2218%22%3E%26%23x23AF%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2222%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22147.5%22%20y%3D%2228%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2222%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22156.5%22%20y%3D%2228%22%3E)%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22166.5%22%20y%3D%2221%22%3E2%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2222%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22119.5%22%20y%3D%2259%22%3En%3C%2Ftext%3E%3C%2Fsvg%3E)
Σ means 'sum of' and
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22horizontalbf65417dcecc7f2b0006e%22%20font-size%3D%2218%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%227.5%22%20y%3D%2213%22%3E%26%23x23AF%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2224%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%226.5%22%20y%3D%2224%22%3Ex%3C%2Ftext%3E%3C%2Fsvg%3E) is another way of writing 'mean' and 'n' is the number of samples taken
is another way of writing 'mean' and 'n' is the number of samples takenWork out individual aspects of the formula first e.g. the mean
Sample results:
Sample site | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
Number of pebbles | 5 | 9 | 10 | 11 | 14 |
Calculate the mean -
%3C%2Fmo%3E%3C%2Fmrow%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xF7%3B%3C%2Fmo%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmn%20mathvariant%3D%22bold%22%3E5%3C%2Fmn%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmo%20mathvariant%3D%22bold%22%3E%3D%3C%2Fmo%3E%3Cmo%20mathvariant%3D%22bold%22%3E%26%23xA0%3B%3C%2Fmo%3E%3Cmn%20mathvariant%3D%22bold%22%3E9%3C%2Fmn%3E%3Cmo%20mathvariant%3D%22bold%22%3E.%3C%2Fmo%3E%3Cmn%20mathvariant%3D%22bold%22%3E8%3C%2Fmn%3E%3C%2Fmath%3E--%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%40font-face%7Bfont-family%3A'math17f76d2330598bf4715bb4879a5'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAAExjdnQgDVUNBwAAAWgAAAA6Z2x5ZoPi2VsAAAGkAAAB5GhlYWQQC2qxAAADiAAAADZoaGVhCGsXSAAAA8AAAAAkaG10eE2rRkcAAAPkAAAAFGxvY2EAHTwYAAAD%2BAAAABhtYXhwBT0FPgAABBAAAAAgbmFtZaBxlY4AAAQwAAABn3Bvc3QB9wD6AAAF0AAAACBwcmVwa1uragAABfAAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEADgAAAAKAAgAAgACACsALgA9APf%2F%2FwAAACsALgA9APf%2F%2F%2F%2FW%2F9T%2Fxv8NAAEAAAAAAAAAAAAAAAABVAMsAIABAABWACoCWAIeAQ4BLAIsAFoBgAKAAKAA1ACAAAAAAAAAACsAVQCAAKsA1QEAASsABwAAAAIAVQAAAwADqwADAAcAADMRIRElIREhVQKr%2FasCAP4AA6v8VVUDAAABAIAAVQLVAqsACwBJARiyDAEBFBMQsQAD9rEBBPWwCjyxAwX1sAg8sQUE9bAGPLENA%2BYAsQAAExCxAQbksQEBExCwBTyxAwTlsQsF9bAHPLEJBOUxMBMhETMRIRUhESMRIYABAFUBAP8AVf8AAasBAP8AVv8AAQAAAQAgAAAAoACAAAMALxgBsAQQsAPUsAMQsALUsAMQsAA8sAIQsAE8ALAEELAD1LADELACPLAAELABPDAxNzMVIyCAgICAAAIAgADrAtUCFQADAAcAZRgBsAgQsAbUsAYQsAXUsAgQsAHUsAEQsADUsAYQsAc8sAUQsAQ8sAEQsAI8sAAQsAM8ALAIELAG1LAGELAH1LAHELAB1LABELAC1LAGELAFPLAHELAEPLABELAAPLACELADPDEwEyE1IR0BITWAAlX9qwJVAcBV1VVVAAMAgACAAwACgAADAAcACwBBGAGwBBCxAAP0sQQH9LAIPLEFEfSwCjyxAQf0sQwD5gCxAwwQ1bEABfWwAxCxCAX1sQsR9bAAELEHBfWxBBH1MDETIRUhATMVIxEzFSOAAoD9gAEAgICAgAGrVgErgP8AgAABAAAAAQAA1XjOQV8PPPUAAwQA%2F%2F%2F%2F%2F9Y6E3P%2F%2F%2F%2F%2F1joTcwAA%2FyAEgAOrAAAACgACAAEAAAAAAAEAAAPo%2F2oAABdwAAD%2FtgSAAAEAAAAAAAAAAAAAAAAAAAAFA1IAVQNWAIAAyAAgA1YAgAOAAIAAAAAAAAAAKAAAAKEAAADnAAABcQAAAeQAAQAAAAUAXgAFAAAAAAACAIAEAAAAAAAEAADeAAAAAAAAABUBAgAAAAAAAAABABIAAAAAAAAAAAACAA4AEgAAAAAAAAADADAAIAAAAAAAAAAEABIAUAAAAAAAAAAFABYAYgAAAAAAAAAGAAkAeAAAAAAAAAAIABwAgQABAAAAAAABABIAAAABAAAAAAACAA4AEgABAAAAAAADADAAIAABAAAAAAAEABIAUAABAAAAAAAFABYAYgABAAAAAAAGAAkAeAABAAAAAAAIABwAgQADAAEECQABABIAAAADAAEECQACAA4AEgADAAEECQADADAAIAADAAEECQAEABIAUAADAAEECQAFABYAYgADAAEECQAGAAkAeAADAAEECQAIABwAgQBNAGEAdABoACAARgBvAG4AdABSAGUAZwB1AGwAYQByAE0AYQB0AGgAcwAgAEYAbwByACAATQBvAHIAZQAgAE0AYQB0AGgAIABGAG8AbgB0AE0AYQB0AGgAIABGAG8AbgB0AFYAZQByAHMAaQBvAG4AIAAxAC4AME1hdGhfRm9udABNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAAAMAAAAAAAAB9AD6AAAAAAAAAAAAAAAAAAAAAAAAAAC5BxEAAI2FGACyAAAAFRQTsQABPw%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'round_brackets18549f92a457f2409'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMjwHLFQAAADMAAAATmNtYXDf7xCrAAABHAAAADxjdnQgBAkDLgAAAVgAAAASZ2x5ZmAOz2cAAAFsAAABJGhlYWQOKih8AAACkAAAADZoaGVhCvgVwgAAAsgAAAAkaG10eCA6AAIAAALsAAAADGxvY2EAAARLAAAC%2BAAAABBtYXhwBIgEWQAAAwgAAAAgbmFtZXHR30MAAAMoAAACOXBvc3QDogHPAAAFZAAAACBwcmVwupWEAAAABYQAAAAHAAAGcgGQAAUAAAgACAAAAAAACAAIAAAAAAAAAQIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAo8AMGe%2F57AAAHPgGyAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACgAKf%2F%2FAAAAKAAp%2F%2F%2F%2F2f%2FZAAEAAAAAAAAAAAFUAFYBAAAsAKgDgAAyAAcAAAACAAAAKgDVA1UAAwAHAAA1MxEjEyMRM9XVq4CAKgMr%2FQAC1QABAAD%2B0AIgBtAACQBNGAGwChCwA9SwAxCwAtSwChCwBdSwBRCwANSwAxCwBzywAhCwCDwAsAoQsAPUsAMQsAfUsAoQsAXUsAoQsADUsAMQsAI8sAcQsAg8MTAREAEzABEQASMAAZCQ%2FnABkJD%2BcALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAA%2FtACIAbQAAkATRgBsAoQsAPUsAMQsALUsAoQsAXUsAUQsADUsAMQsAc8sAIQsAg8ALAKELAD1LADELAH1LAKELAF1LAKELAA1LADELACPLAHELAIPDEwARABIwAREAEzAAIg%2FnCQAZD%2BcJABkALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAAAAEAAPW2NYFfDzz1AAMIAP%2F%2F%2F%2F%2FVre7u%2F%2F%2F%2F%2F9Wt7u4AAP7QA7cG0AAAAAoAAgABAAAAAAABAAAHPv5OAAAXcAAA%2F%2F4DtwABAAAAAAAAAAAAAAAAAAAAAwDVAAACIAAAAiAAAAAAAAAAAAAkAAAAowAAASQAAQAAAAMACgACAAAAAAACAIAEAAAAAAAEAABNAAAAAAAAABUBAgAAAAAAAAABAD4AAAAAAAAAAAACAA4APgAAAAAAAAADAFwATAAAAAAAAAAEAD4AqAAAAAAAAAAFABYA5gAAAAAAAAAGAB8A%2FAAAAAAAAAAIABwBGwABAAAAAAABAD4AAAABAAAAAAACAA4APgABAAAAAAADAFwATAABAAAAAAAEAD4AqAABAAAAAAAFABYA5gABAAAAAAAGAB8A%2FAABAAAAAAAIABwBGwADAAEECQABAD4AAAADAAEECQACAA4APgADAAEECQADAFwATAADAAEECQAEAD4AqAADAAEECQAFABYA5gADAAEECQAGAB8A%2FAADAAEECQAIABwBGwBSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAAUgBvAHUAbgBkACAAYgByAGEAYwBrAGUAdABzACAAdwBpAHQAaAAgAGEAcwBjAGUAbgB0ACAAMQA4ADUANABSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFYAZQByAHMAaQBvAG4AIAAyAC4AMFJvdW5kX2JyYWNrZXRzX3dpdGhfYXNjZW50XzE4NTQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAADnwHPAAAAAAAAAAAAAAAAAAAAAAAAAAC5B%2F8AAY2FAA%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2218%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%224.5%22%20y%3D%2216%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2218%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2212.5%22%20y%3D%2216%22%3E5%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17f76d2330598bf4715bb4879a5%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2226.5%22%20y%3D%2216%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2218%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2240.5%22%20y%3D%2216%22%3E9%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17f76d2330598bf4715bb4879a5%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2254.5%22%20y%3D%2216%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2218%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2273.5%22%20y%3D%2216%22%3E10%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17f76d2330598bf4715bb4879a5%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2292.5%22%20y%3D%2216%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2218%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22111.5%22%20y%3D%2216%22%3E11%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17f76d2330598bf4715bb4879a5%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22130.5%22%20y%3D%2216%22%3E%2B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2218%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22149.5%22%20y%3D%2216%22%3E14%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2218%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22162.5%22%20y%3D%2216%22%3E)%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17f76d2330598bf4715bb4879a5%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22180.5%22%20y%3D%2216%22%3E%26%23xF7%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2218%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22200.5%22%20y%3D%2216%22%3E5%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17f76d2330598bf4715bb4879a5%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22219.5%22%20y%3D%2216%22%3E%3D%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2218%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22238.5%22%20y%3D%2216%22%3E9%3C%2Ftext%3E%3Ctext%20font-family%3D%22math17f76d2330598bf4715bb4879a5%22%20font-size%3D%2216%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22246.5%22%20y%3D%2216%22%3E.%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2218%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%22254.5%22%20y%3D%2216%22%3E8%3C%2Ftext%3E%3C%2Fsvg%3E)
Calculate
format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math1da40657c9fece7e48d30af42d3'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAADRjdnQgDVUNBwAAAVAAAAA6Z2x5ZoPi2VsAAAGMAAAAcmhlYWQQC2qxAAACAAAAADZoaGVhCGsXSAAAAjgAAAAkaG10eE2rRkcAAAJcAAAACGxvY2EAHTwYAAACZAAAAAxtYXhwBT0FPgAAAnAAAAAgbmFtZaBxlY4AAAKQAAABn3Bvc3QB9wD6AAAEMAAAACBwcmVwa1uragAABFAAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACAAAAAEAAQAAQAAIhL%2F%2FwAAIhL%2F%2F93vAAEAAAAAAAABVAMsAIABAABWACoCWAIeAQ4BLAIsAFoBgAKAAKAA1ACAAAAAAAAAACsAVQCAAKsA1QEAASsABwAAAAIAVQAAAwADqwADAAcAADMRIRElIREhVQKr%2FasCAP4AA6v8VVUDAAABAIABVQLVAasAAwAwGAGwBBCxAAP2sAM8sQIH9bABPLEFA%2BYAsQAAExCxAAblsQABExCwATyxAwX1sAI8EyEVIYACVf2rAatWAAAAAQAAAAEAANV4zkFfDzz1AAMEAP%2F%2F%2F%2F%2FWOhNz%2F%2F%2F%2F%2F9Y6E3MAAP8gBIADqwAAAAoAAgABAAAAAAABAAAD6P9qAAAXcAAA%2F7YEgAABAAAAAAAAAAAAAAAAAAAAAgNSAFUDVgCAAAAAAAAAACgAAAByAAEAAAACAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%225.5%22%20y%3D%2220%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1da40657c9fece7e48d30af42d3%22%20font-size%3D%2217%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2221.5%22%20y%3D%2220%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22horizontalbf65417dcecc7f2b0006e%22%20font-size%3D%2215%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2236.5%22%20y%3D%2211%22%3E%26%23x23AF%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2236.5%22%20y%3D%2220%22%3Ex%3C%2Ftext%3E%3C%2Fsvg%3E) for each number
for each numberSquare each of those values (the square of a negative number becomes positive)
Add the squared values to give
%3C%2Fmo%3E%3C%2Fmrow%3E%3C%2Fmstyle%3E%3C%2Fmath%3E--%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%40font-face%7Bfont-family%3A'horizontalbf65417dcecc7f2b0006e'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMlJxIOAAAADMAAAATmNtYXCwg0j%2FAAABHAAAADRjdnQgAAcAAAAAAVAAAAACZ2x5ZuwE1kUAAAFUAAAAO2hlYWQNciGiAAABkAAAADZoaGVhBusXCAAAAcgAAAAkaG10eGjtB6sAAAHsAAAACGxvY2EAAYSYAAAB9AAAAAxtYXhwBLEEbgAAAgAAAAAgbmFtZReja%2F8AAAIgAAAByXBvc3QB9wD6AAAD7AAAACBwcmVwu5WEAAAABAwAAAAHAAACRwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAACOv8xEDev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACAAAAAEAAQAAQAAI6%2F%2F%2FwAAI6%2F%2F%2F9xSAAEAAAAAAAcAAAABAAABVQGrAasAAwAjGAGwBBCwATywARCwAtSwAhCwBTwAsAQQsAHUsAEQsADUMDERFSE1AasBq1ZWAAABAAAAAQAARVMXc18PPPUAAwQA%2F%2F%2F%2F%2F9Wt7tH%2F%2F%2F%2F%2F1a3u0QAAAAADAAMAAAAACgACAAEAAAAAAAEAAAPo%2F2oAABdwAAD%2F%2FwMAAAEAAAAAAAAAAAAAAAAAAAACAyAAAAGrAAAAAAAAAAAAAAAAADsAAQAAAAIADQACAAAAAAACAIAEAAAAAAAEAABfAAAAAAAAABUBAgAAAAAAAAABAB4AAAAAAAAAAAACAA4AHgAAAAAAAAADADwALAAAAAAAAAAEAB4AaAAAAAAAAAAFABYAhgAAAAAAAAAGAA8AnAAAAAAAAAAIABwAqwABAAAAAAABAB4AAAABAAAAAAACAA4AHgABAAAAAAADADwALAABAAAAAAAEAB4AaAABAAAAAAAFABYAhgABAAAAAAAGAA8AnAABAAAAAAAIABwAqwADAAEECQABAB4AAAADAAEECQACAA4AHgADAAEECQADADwALAADAAEECQAEAB4AaAADAAEECQAFABYAhgADAAEECQAGAA8AnAADAAEECQAIABwAqwBIAG8AcgBpAHoAbwBuAHQAYQBsACAARgBvAG4AdABSAGUAZwB1AGwAYQByAE0AYQB0AGgAcwAgAEYAbwByACAATQBvAHIAZQAgAEgAbwByAGkAegBvAG4AdABhAGwAIABGAG8AbgB0AEgAbwByAGkAegBvAG4AdABhAGwAIABGAG8AbgB0AFYAZQByAHMAaQBvAG4AIAAxAC4AMEhvcml6b250YWxfRm9udABNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAAAAAAwAAAAAAAAH0APoAAAAAAAAAAAAAAAAAAAAAAAAAALkH%2FwACjYUA)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'math1da40657c9fece7e48d30af42d3'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMi7iBBMAAADMAAAATmNtYXDEvmKUAAABHAAAADRjdnQgDVUNBwAAAVAAAAA6Z2x5ZoPi2VsAAAGMAAAAcmhlYWQQC2qxAAACAAAAADZoaGVhCGsXSAAAAjgAAAAkaG10eE2rRkcAAAJcAAAACGxvY2EAHTwYAAACZAAAAAxtYXhwBT0FPgAAAnAAAAAgbmFtZaBxlY4AAAKQAAABn3Bvc3QB9wD6AAAEMAAAACBwcmVwa1uragAABFAAAAAUAAADSwGQAAUAAAQABAAAAAAABAAEAAAAAAAAAQEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAg1UADev96AAAD6ACWAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACAAAAAEAAQAAQAAIhL%2F%2FwAAIhL%2F%2F93vAAEAAAAAAAABVAMsAIABAABWACoCWAIeAQ4BLAIsAFoBgAKAAKAA1ACAAAAAAAAAACsAVQCAAKsA1QEAASsABwAAAAIAVQAAAwADqwADAAcAADMRIRElIREhVQKr%2FasCAP4AA6v8VVUDAAABAIABVQLVAasAAwAwGAGwBBCxAAP2sAM8sQIH9bABPLEFA%2BYAsQAAExCxAAblsQABExCwATyxAwX1sAI8EyEVIYACVf2rAatWAAAAAQAAAAEAANV4zkFfDzz1AAMEAP%2F%2F%2F%2F%2FWOhNz%2F%2F%2F%2F%2F9Y6E3MAAP8gBIADqwAAAAoAAgABAAAAAAABAAAD6P9qAAAXcAAA%2F7YEgAABAAAAAAAAAAAAAAAAAAAAAgNSAFUDVgCAAAAAAAAAACgAAAByAAEAAAACAF4ABQAAAAAAAgCABAAAAAAABAAA3gAAAAAAAAAVAQIAAAAAAAAAAQASAAAAAAAAAAAAAgAOABIAAAAAAAAAAwAwACAAAAAAAAAABAASAFAAAAAAAAAABQAWAGIAAAAAAAAABgAJAHgAAAAAAAAACAAcAIEAAQAAAAAAAQASAAAAAQAAAAAAAgAOABIAAQAAAAAAAwAwACAAAQAAAAAABAASAFAAAQAAAAAABQAWAGIAAQAAAAAABgAJAHgAAQAAAAAACAAcAIEAAwABBAkAAQASAAAAAwABBAkAAgAOABIAAwABBAkAAwAwACAAAwABBAkABAASAFAAAwABBAkABQAWAGIAAwABBAkABgAJAHgAAwABBAkACAAcAIEATQBhAHQAaAAgAEYAbwBuAHQAUgBlAGcAdQBsAGEAcgBNAGEAdABoAHMAIABGAG8AcgAgAE0AbwByAGUAIABNAGEAdABoACAARgBvAG4AdABNAGEAdABoACAARgBvAG4AdABWAGUAcgBzAGkAbwBuACAAMQAuADBNYXRoX0ZvbnQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAADAAAAAAAAAfQA%2BgAAAAAAAAAAAAAAAAAAAAAAAAAAuQcRAACNhRgAsgAAABUUE7EAAT8%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%40font-face%7Bfont-family%3A'round_brackets18549f92a457f2409'%3Bsrc%3Aurl(data%3Afont%2Ftruetype%3Bcharset%3Dutf-8%3Bbase64%2CAAEAAAAMAIAAAwBAT1MvMjwHLFQAAADMAAAATmNtYXDf7xCrAAABHAAAADxjdnQgBAkDLgAAAVgAAAASZ2x5ZmAOz2cAAAFsAAABJGhlYWQOKih8AAACkAAAADZoaGVhCvgVwgAAAsgAAAAkaG10eCA6AAIAAALsAAAADGxvY2EAAARLAAAC%2BAAAABBtYXhwBIgEWQAAAwgAAAAgbmFtZXHR30MAAAMoAAACOXBvc3QDogHPAAAFZAAAACBwcmVwupWEAAAABYQAAAAHAAAGcgGQAAUAAAgACAAAAAAACAAIAAAAAAAAAQIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgICAAAAAo8AMGe%2F57AAAHPgGyAAAAAAACAAEAAQAAABQAAwABAAAAFAAEACgAAAAGAAQAAQACACgAKf%2F%2FAAAAKAAp%2F%2F%2F%2F2f%2FZAAEAAAAAAAAAAAFUAFYBAAAsAKgDgAAyAAcAAAACAAAAKgDVA1UAAwAHAAA1MxEjEyMRM9XVq4CAKgMr%2FQAC1QABAAD%2B0AIgBtAACQBNGAGwChCwA9SwAxCwAtSwChCwBdSwBRCwANSwAxCwBzywAhCwCDwAsAoQsAPUsAMQsAfUsAoQsAXUsAoQsADUsAMQsAI8sAcQsAg8MTAREAEzABEQASMAAZCQ%2FnABkJD%2BcALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAA%2FtACIAbQAAkATRgBsAoQsAPUsAMQsALUsAoQsAXUsAUQsADUsAMQsAc8sAIQsAg8ALAKELAD1LADELAH1LAKELAF1LAKELAA1LADELACPLAHELAIPDEwARABIwAREAEzAAIg%2FnCQAZD%2BcJABkALQ%2FZD%2BcAGQAnACcAGQ%2FnAAAQAAAAEAAPW2NYFfDzz1AAMIAP%2F%2F%2F%2F%2FVre7u%2F%2F%2F%2F%2F9Wt7u4AAP7QA7cG0AAAAAoAAgABAAAAAAABAAAHPv5OAAAXcAAA%2F%2F4DtwABAAAAAAAAAAAAAAAAAAAAAwDVAAACIAAAAiAAAAAAAAAAAAAkAAAAowAAASQAAQAAAAMACgACAAAAAAACAIAEAAAAAAAEAABNAAAAAAAAABUBAgAAAAAAAAABAD4AAAAAAAAAAAACAA4APgAAAAAAAAADAFwATAAAAAAAAAAEAD4AqAAAAAAAAAAFABYA5gAAAAAAAAAGAB8A%2FAAAAAAAAAAIABwBGwABAAAAAAABAD4AAAABAAAAAAACAA4APgABAAAAAAADAFwATAABAAAAAAAEAD4AqAABAAAAAAAFABYA5gABAAAAAAAGAB8A%2FAABAAAAAAAIABwBGwADAAEECQABAD4AAAADAAEECQACAA4APgADAAEECQADAFwATAADAAEECQAEAD4AqAADAAEECQAFABYA5gADAAEECQAGAB8A%2FAADAAEECQAIABwBGwBSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFIAZQBnAHUAbABhAHIATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlACAAUgBvAHUAbgBkACAAYgByAGEAYwBrAGUAdABzACAAdwBpAHQAaAAgAGEAcwBjAGUAbgB0ACAAMQA4ADUANABSAG8AdQBuAGQAIABiAHIAYQBjAGsAZQB0AHMAIAB3AGkAdABoACAAYQBzAGMAZQBuAHQAIAAxADgANQA0AFYAZQByAHMAaQBvAG4AIAAyAC4AMFJvdW5kX2JyYWNrZXRzX3dpdGhfYXNjZW50XzE4NTQATQBhAHQAaABzACAARgBvAHIAIABNAG8AcgBlAAAAAAMAAAAAAAADnwHPAAAAAAAAAAAAAAAAAAAAAAAAAAC5B%2F8AAY2FAA%3D%3D)format('truetype')%3Bfont-weight%3Anormal%3Bfont-style%3Anormal%3B%7D%3C%2Fstyle%3E%3C%2Fdefs%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-style%3D%22italic%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%226.5%22%20y%3D%2220%22%3E%26%23x3A3%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2219.5%22%20y%3D%2220%22%3E(%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2227.5%22%20y%3D%2220%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22math1da40657c9fece7e48d30af42d3%22%20font-size%3D%2217%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2242.5%22%20y%3D%2220%22%3E%26%23x2212%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22horizontalbf65417dcecc7f2b0006e%22%20font-size%3D%2215%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2257.5%22%20y%3D%2211%22%3E%26%23x23AF%3B%3C%2Ftext%3E%3Ctext%20font-family%3D%22Times%20New%20Roman%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2257.5%22%20y%3D%2220%22%3Ex%3C%2Ftext%3E%3Ctext%20font-family%3D%22round_brackets18549f92a457f2409%22%20font-size%3D%2220%22%20font-weight%3D%22bold%22%20text-anchor%3D%22middle%22%20x%3D%2266.5%22%20y%3D%2220%22%3E)%3C%2Ftext%3E%3C%2Fsvg%3E)
Divide the total by 'n'
Finally, find the square root
|
|
| (x-x¯) |
|---|---|---|---|
5 | 9.8 | -4.8 | 23.04 |
9 | 9.8 | -0.8 | 0.64 |
10 | 9.8 | 0.2 | 0.04 |
11 | 9.8 | 1.2 | 1.44 |
14 | 9.8 | 4.2 | 17.64 |
Σ = 42.8 | |||
σ = 42.85 = 2.93 (2 dp)
Numbers closely grouped around the mean shows a small deviation
A large standard deviation would show a set of numbers that were spread out
Spearman's rank correlation coefficient
A test to determine if two sets of numbers have a relationship
Not the easiest to calculate
Σ means 'sum of', d is the difference and 'n' is the number of samples taken
The formula is rs = 1 - 6∑d2n3 - n
Rank each number in both sets of data, with the highest number given rank 1, second highest 2 etc.
Calculate 'd' which is the difference between ranks of each group e.g. ranks for group 5 are 4 and 6; difference will be 2
Square value 'd' and calculate the total d2 to find ∑d2
Finally, calculate the coefficient of rs using the above formula
The resulting number should always be between -1 and +1
GNP ($) per capita and Life Expectancy (years)
Country | GNP | Rank | Life Expectancy | Rank | d | d2 |
|---|---|---|---|---|---|---|
1 | 15,124 | 5 | 73 | 5 | 0 | 0 |
2 | 20,535 | 4 | 72 | 6 | 2 | 4 |
3 | 10.432 | 9 | 68 | 8 | 1 | 1 |
4 | 7,050 | 11 | 62 | 11 | 0 | 0 |
5 | 22,950 | 3 | 76 | 3 | 0 | 0 |
6 | 14,800 | 6 | 75 | 4 | 2 | 4 |
7 | 23,752 | 2 | 77 | 2 | 0 | 0 |
8 | 36,875 | 1 | 79 | 1 | 0 | 0 |
9 | 5,525 | 12 | 61 | 12 | 0 | 0 |
10 | 8,678 | 10 | 66 | 9 | 1 | 1 |
11 | 12,211 | 8 | 65 | 10 | 2 | 4 |
12 | 13,500 | 7 | 70 | 7 | 0 | 0 |
n=12 | Σd2 = 14 | |||||
Σd2 = 14 and n =12.
rs =1 -6 ×14123 - 12 = 1- 841716 =1-0.048951 (0.05) = 0.95
(0.048951 can be rounded to 2 decimal places giving 0.05)
A positive result shows a positive correlation, where one variable increases so does the other
The closer the number is to 1, the stronger the positive correlation
A negative results shows a negative correlation, where one variable increases the other decreases
The closer the number is to -1 the stronger the negative correlation
If however, the correlation is 0 or near to 0, there is no relationship
Determining significance
Spearman's rank may show that two sets of numbers are correlated, however, it does not show how significant the link between the two values are
To check for significance; a table of critical values or a graph is needed
This looks at the probability of the links occurring by chance
A 5% or higher probability of chance is not significant evidence for a link
1% or less is a significant evidence of a link
This is the significance level of a statistical test
The degrees of freedom needs calculating - n-2
Using the example above: 12 - 2 = 10 degrees of freedom
As rs = 0.95 then the correlation has a less than 1% probability of being by chance
Therefore, there is a high significance level of a relationship between GNP and life expectancy
Spearman’s Rank Correlation Significance Table
Degrees of Freedom | 5% (0.05) | 1% (0.01) |
|---|---|---|
8 | 0.72 | 0.84 |
9 | 0.68 | 0.80 |
10 | 0.64 | 0.77 |
11 | 0.60 | 0.74 |
12 | 0.57 | 0.71 |
13 | 0.54 | 0.69 |
14 | 0.52 | 0.67 |
15 | 0.50 | 0.65 |
20 | 0.47 | 0.59 |
Examiner Tips and Tricks
Always check when making calculations what the question has asked you to do. Is it asking for units to be stated or calculate to the nearest whole number or quote to 2 decimal places.

You've read 0 of your 5 free revision notes this week
Unlock more, it's free!
Did this page help you?
